
We’ve seen how difficult it is for large multinationals to adapt their IT infrastructure. Stringent regulations, such as the GDPR and Basel III, are among the biggest threats to organizations. But, rather than fighting these changes, your business should adapt.
An effective compliance strategy is the answer.
In particular, the banking and financial services industry will need to embrace this new reality. Transparency and governance are now the main driving forces in business. As such, you'll need data integration processes that eliminate ad-hoc and siloed data feeds.
Ultimately, the right data integration approach facilitates a strong regulatory and risk compliance strategy.
What is a regulatory compliance strategy and why is it important?
Here's a definition of compliance strategy:A regulatory compliance strategy is the plan of action to achieve compliance for your business. In short, regulatory compliance is when a business follows state, federal, and international laws and regulations relevant to its operations. The specific requirements of these can vary, depending largely on the industry and type of business. Regulatory compliance is shaped by your sector, your business and where you do business, too. For example, GDPR is an important consideration for any business trading in Europe.
Here's a definition of compliance strategy: the plan of action to achieve regulatory compliance for your business. Naturally, it's shaped by your sector, your business and where you do business. For example, GDPR is an important consideration for any business trading in Europe.
Ever since the financial crash in 2007, banks and other financial services have been subject to stricter operational laws and regulations. While some of these regulations are industry-specific, many are cross-disciplinary and affect all the businesses in a particular country or region.
While you’re probably already aware of the regulations in your industry, it’s important to remember why they exist. These laws ensure the safety, integrity and ethical use of customer data, preventing exploitation and corruption.

Failure to comply with these regulations can lead to high-profile data breaches and subsequent lawsuits. Not something you need on your record. Unfortunately, it only takes one bad audit to land yourself in particularly hot water. And, for this reason, it’s important you have a way to continuously track data lineage and ensure the integrity of your data throughout its entire lifecycle.
Webinar: Turn Data Models into ETL Jobs at the Click of a ButtonWith a continued push towards globalization and hybrid infrastructure, reducing your reliance on manual and tedious integration processes is critical. But quick-fix solutions to near-term problems are no longer enough.
The challenges of traditional regulatory compliance strategies
Typically, many organizations attempt to capture knowledge about their data in some sort of data models. Either you’re lucky enough to have a comprehensive strategy for creating, updating and maintaining formal data models or you just operate on ad-hoc basis. In scenario two, documentation and individual efforts to capture data structures and processes are often buried in code, script, database schemas, etc.
Regardless of which method you apply, there is usually a divide between models (static documentation) and constantly changing code and schemas. With little data governance, you limit your ability to report and audit what is actually happening to your data.
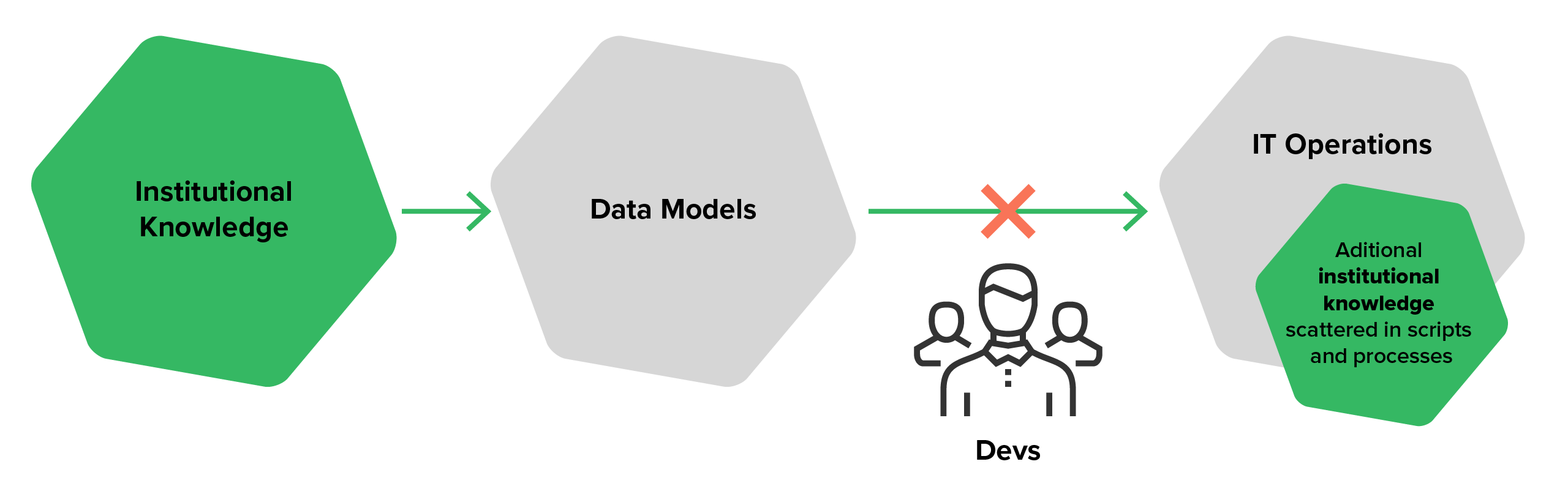
With thousands of unorganized point-to-point data feeds, confusion, duplication and dataset divergence is inevitable. Add in the complexity of regulatory corrective and aggregation processes and you're spending more time managing your data than using it. In this scenario, your only choice is to spend hard-earned cash on complex reconciliation and validation processes to avoid compliance risk.
If this is your current set-up, the following problems may look familiar:
- Fragmented or lost institutional knowledge
- Increased costs to maintain corrective processes
- Lack of organizational control and visibility.
- Complicated dialogue with regulators
- Dataset divergence and multiple versions of the truth
- Little to no standardized data governance
This spells trouble for organizations which need clear and auditable data trails to prevent penalties and fines. At this point, you need to find a smarter way to translate your business goals into actionable run-time processes to avoid damage to your reputation and bottom line.
Overcoming the Data Challenges in Financial Services Reporting and AnalysisThe importance of bridging data models and IT operations
So, how can organizations under increasing regulatory pressure organize, document, and execute their data flows in a controlled, transparent, and auditable way?
The key to success is to shorten the path between your ‘metadata’ – what your data structures and processes should look like - and their actual implementation. But getting your data to the right place at the right time takes more than a documentation-then-implementation approach.
Instead, businesses need to shift to an instant deployment approach, where data models translate automatically into operational functions, without the need for lengthy projects and development energy. This enables business users or analysts to work more transparently with the data and gain a greater understanding of the underlying infrastructure.
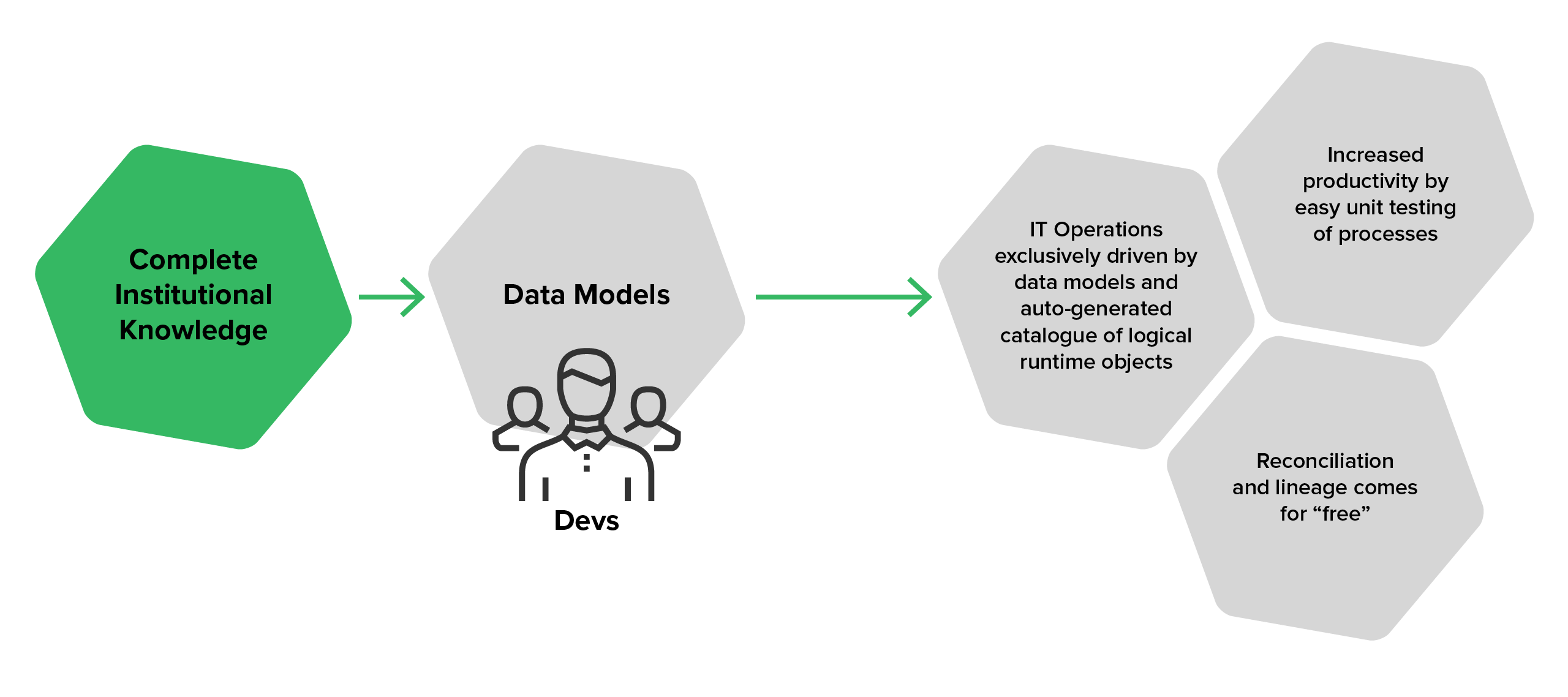
Using this method, large organizations can shave months off the time it takes to develop new integrations, directly improving their ability to react to market changes.
And with a direction connection between your data models and the underlying infrastructure, you move away from confusing silo management and de-duplication processes towards a holy grail of transparency, trust, auditability, and full automation.
Watch our video on making data models actionable to see this approach in action.
The process
With the right data integration platform, you can move from scattered and siloed implementations to a centralized metadata repository and document your core processes both at a high level and in detail.
Not only does this help simplify your specifications, it also provides a clear and manageable way to turn your existing business logic, data sources, and data targets into a powerful new set of integrations.
Changes and additions take only a few days to put into production, instead of the months you currently spend on IT development. And, over time, you can further improve runtime execution by analyzing performance and optimizing your deployment patterns.
Benefits of the data-model-first approach
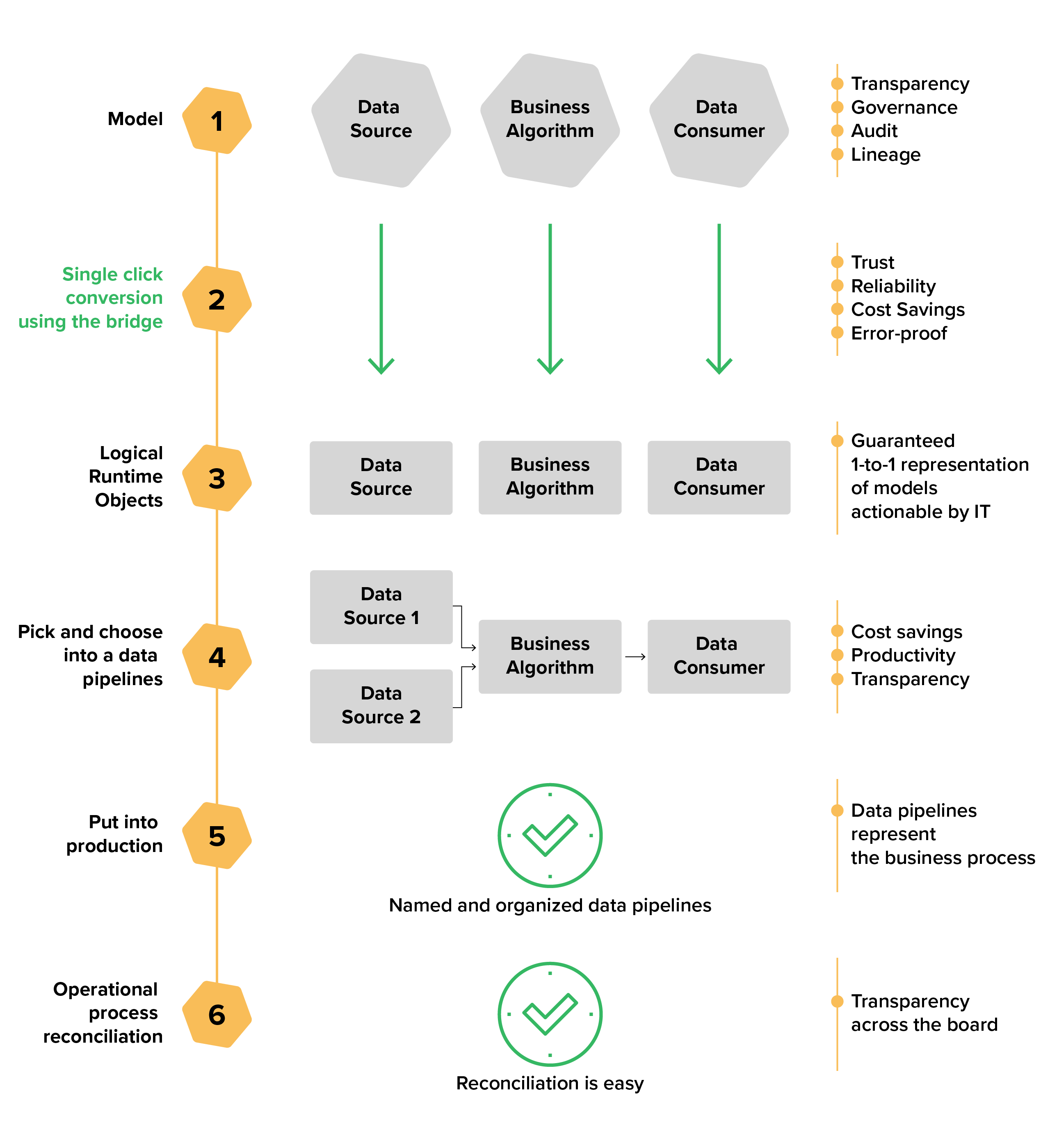
- Lineage and governance at no extra cost
- The alignment of business unit data and processes to central group information model
- A single point of validation with easier data quality across standardized model
- Centralized reconciliation
- Easy to visualize data models to capture and share institutional knowledge
- Common definitions and meanings for all business users
- Auto-generated catalogue of logical run-time objects
- Automatic unit testing for business algorithms, leading to higher productivity and quicker time to value
While regulatory requirements are putting increasing pressure on organizations, you don’t have to struggle through with the same old routine. By building a stronger relationship between your data models and data integration processes, you have the opportunity to simplify the complexity of your data pipelines and ensure unprecedented levels of transparency across all your business processes.
This should be on the radar of every business looking to achieve a modern compliance management strategy. After all, as your business modernizes and handles more data, it makes sense to consider it part of your wider compliance modernization efforts.
To find out how you can make this a reality in your organization, learn more about the CloverDX data modeling bridge.

Share







